Experiment: Inspired by the GoodAI General AI Challenge Task#1, a character is chosen at random that the agent should always output. During training, the random character is changed without warning, so the Agent needs to adapt on the fly and detect that the character has changed and output the new character.
Learning/Recall: This experiment uses Online-learning to dynamically adapt as the expected random character is changed, so the Agent uses recall to respond to the input and then learns from the resultant input generated by the environment.
Results: The Agent learns each random character after one to two steps of each discovered instance, however it would often take up to nine steps to unlearn a character.
Learning/Recall: This experiment uses Online-learning to dynamically adapt as the expected random character is changed, so the Agent uses recall to respond to the input and then learns from the resultant input generated by the environment.
Results: The Agent learns each random character after one to two steps of each discovered instance, however it would often take up to nine steps to unlearn a character.

AI Challenge - Task# 01
The Experiments
All experiments have been designed to test the learning and planning abilities of the NeuroLife Artificial Intelligence technology.
The long-term goal is to build an Artificial General Intelligence technology capable of automating processes from human commands.
The long-term goal is to build an Artificial General Intelligence technology capable of automating processes from human commands.

Experiment: In this 3D experiment, again the sensors are hardcoded to objects in a 3D world, now with the addition of an "atBase" sensor.
Learning: During the learning-phase of the experiment, again the user uses neural-stimulation to move the Agent around the world, however this time the agent is also trained by the user to hold and carry the cube to the base.
Recall: To test the Agent, the "atCube", "handTouching" and "atBase" sensors are simultaneously stimulated as a goal-state while the Agent is not near the cube. Assuming the Agent has been properly trained by the user, the Agent moves to and touches the cube, however it then continues to hold the cube and carry it to the base.
Results: The Agent learned this task after three user-trained sequences of approaching and touching the cube and carrying the cube to the base.
Learning: During the learning-phase of the experiment, again the user uses neural-stimulation to move the Agent around the world, however this time the agent is also trained by the user to hold and carry the cube to the base.
Recall: To test the Agent, the "atCube", "handTouching" and "atBase" sensors are simultaneously stimulated as a goal-state while the Agent is not near the cube. Assuming the Agent has been properly trained by the user, the Agent moves to and touches the cube, however it then continues to hold the cube and carry it to the base.
Results: The Agent learned this task after three user-trained sequences of approaching and touching the cube and carrying the cube to the base.
The agent learns to carry a cube to the base
Early Experimentation - Learning and Planning (using a 3rd party Neural Net)
The early experiments were created to test the learning and planning abilities of the NeuroLife Learning engine coupled with the NeuroSolutions neural network.
Recent Experiments - Learning and Planning (using a custom Neural Net)
The recent experiments were created to test the learning and planning abilities of the NeuroLife learning engine coupled with an artificial neural network developed in-house. The sensors are no longer hard-coded to known objects, they instead sense attributes of the world in relation to the Agent's body. For example, the Agent can sense the color and distance to the object within its current focus of attention.
Experiment: Inspired by the GoodAI General AI Challenge Task#2, the Agent is trained to discover a mapping between each symbol on the input and a required output symbol. There are several groups of symbols on the input and all symbols within one group are mapped to the same character. During training, the mappings are changed without warning, so the Agent needs to adapt on the fly.
Learning/Recall: This experiment uses Online-learning to dynamically adapt as the expected random character is changed, so the Agent initially uses trial-end-error and later recall to respond to the input and then learns from the input generated by the environment as a result of the Agent input.
Results: The Agent learned to correctly map the response to each instance of this target after one to two steps of each discovered instance, however it often takes up to nine steps to unlearn a mapping.
Learning/Recall: This experiment uses Online-learning to dynamically adapt as the expected random character is changed, so the Agent initially uses trial-end-error and later recall to respond to the input and then learns from the input generated by the environment as a result of the Agent input.
Results: The Agent learned to correctly map the response to each instance of this target after one to two steps of each discovered instance, however it often takes up to nine steps to unlearn a mapping.
AI Challenge - Task# 02


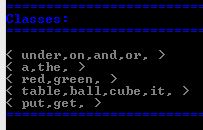
Experiment: In this experiment, the Agent discovers word-classes from simple sentences.
Learning: During the learning-phase of the experiment, unsupervised learning is used to allow the Agent to discover word-patterns across a list of simple sentences. The discovered patterns are then used to assign each word to a class.
Recall: To test the Agent, the list of discovered classes is displayed to allow comparison with expected parts-of-speech classifications.
Results: The Agent was able to classify parts-of-speech across simple sentences with a high degree of accuracy and without any external guidance or rewarding. Further refinement is required with this experiment to prevent the occasional sharing of a class.
Learning: During the learning-phase of the experiment, unsupervised learning is used to allow the Agent to discover word-patterns across a list of simple sentences. The discovered patterns are then used to assign each word to a class.
Recall: To test the Agent, the list of discovered classes is displayed to allow comparison with expected parts-of-speech classifications.
Results: The Agent was able to classify parts-of-speech across simple sentences with a high degree of accuracy and without any external guidance or rewarding. Further refinement is required with this experiment to prevent the occasional sharing of a class.
Discover Word Classes


> look red cube
Experiment: In this 2D experiment, the Agent is trained to respond to the text "look red cube" by focussing on the red cube.
Learning: During the learning-phase of the experiment, the Agent is rewarded for focussing on the red cube after receiving the text "look red cube".
Recall: To test the Agent, the Agent is initialized with its focus on the blue cube and is then presented with the text "look red cub" resulting in the Agent focussing on the red cube.
Results: The Agent learned this task after two training instances.
Learning: During the learning-phase of the experiment, the Agent is rewarded for focussing on the red cube after receiving the text "look red cube".
Recall: To test the Agent, the Agent is initialized with its focus on the blue cube and is then presented with the text "look red cub" resulting in the Agent focussing on the red cube.
Results: The Agent learned this task after two training instances.
Respond to the text "look red cube"

The agent learns to navigate itself to the cube and touch the cube
Experiment: In this 3D experiment, the sensors are hardcoded to objects in a 3D world. For example, the cube is sensed using the "cube" sensor and the base is sensed using the "base" sensor. Agent states are also hardcoded. For example, the state for being at a cube is detected by the "atCube" sensor.
Learning: During the learning-phase of the experiment, the user uses neural-stimulation to move the Agent around the world and to approach and touch each object.
Recall: To test the Agent, the "atCube" and "handTouching" sensors are simultaneously stimulated as a goal-state while the Agent is not near the cube. Assuming the Agent has been properly trained by the user, the Agent moves toward the cube until it is at the cube and then touches the cube.
Results: The Agent learned this task after three user-trained sequences of approaching and touching the cube.
Learning: During the learning-phase of the experiment, the user uses neural-stimulation to move the Agent around the world and to approach and touch each object.
Recall: To test the Agent, the "atCube" and "handTouching" sensors are simultaneously stimulated as a goal-state while the Agent is not near the cube. Assuming the Agent has been properly trained by the user, the Agent moves toward the cube until it is at the cube and then touches the cube.
Results: The Agent learned this task after three user-trained sequences of approaching and touching the cube.


Experiment: In this 2D experiment, the Agent is trained to move left when at a selected location on the right and to move right when at a selected location on the left, causing a perpetual bounce behaviour.
Learning: During the learning-phase of the experiment, the Agent is rewarded for moving right at a selected location on the left, and again rewarded for moving left at a selected location on the right.
Recall: To test the Agent, the Agent is positioned at the left location which triggers the Agent's learned bounce behaviour.
Results: The Agent learned this task after two training instances.
Learning: During the learning-phase of the experiment, the Agent is rewarded for moving right at a selected location on the left, and again rewarded for moving left at a selected location on the right.
Recall: To test the Agent, the Agent is positioned at the left location which triggers the Agent's learned bounce behaviour.
Results: The Agent learned this task after two training instances.
Bounce between locations
> is red ?
> yes
Experiment: In this 2D experiment, the Agent is trained to respond to the text "is red ?" by answering with "yes" if the assertion is true.
Learning: During the learning-phase of the experiment, the Agent is first taught to associate the words "red", and "blue" with their respective colours. The Agent is then taught to respond with "yes" when it senses a colour and is then presented with text in the form of "is <colour> ?".
Recall: To test the Agent, the Agent focus is set to focus on the red cube and is then presented with the text "is red ?" allowing the Agent to respond with the text "> yes".
Results: The Agent learned this task after two training instances.
Learning: During the learning-phase of the experiment, the Agent is first taught to associate the words "red", and "blue" with their respective colours. The Agent is then taught to respond with "yes" when it senses a colour and is then presented with text in the form of "is <colour> ?".
Recall: To test the Agent, the Agent focus is set to focus on the red cube and is then presented with the text "is red ?" allowing the Agent to respond with the text "> yes".
Results: The Agent learned this task after two training instances.
Respond to the text "is red ?"
Experiment: In this 3D experiment, the Agent is trained to reach for a cube.
Learning: During the learning-phase of the experiment, neural-stimulation is used to move the Agent's hand toward and away from the cube. The Agent is rewarded whenever its hand touches the cube.
Recall: To test the Agent, the Agent's arm begins in a rest position near the cube and is then allowed to recall its reward states associated with the Agent's hand being closer to the cube..
Results: The Agent learned this task after less than 10 seconds of moving and rewarding hand positions.
Learning: During the learning-phase of the experiment, neural-stimulation is used to move the Agent's hand toward and away from the cube. The Agent is rewarded whenever its hand touches the cube.
Recall: To test the Agent, the Agent's arm begins in a rest position near the cube and is then allowed to recall its reward states associated with the Agent's hand being closer to the cube..
Results: The Agent learned this task after less than 10 seconds of moving and rewarding hand positions.
Reaching for a cube

> look blue cube then red cube
Experiment: In this 2D experiment, the Agent is trained to respond to the text "look blue cube then red cube" by focussing on the blue cube followed by focussing on the red cube.
Learning: During the learning-phase of the experiment, the Agent is rewarded for focussing on the blue cube followed by focussing on the red cube after receiving the text "look blue cube then red cube".
Recall: To test the Agent, the Agent is initialized with its focus on the blue cube and is then presented with the text "look blue cube then red cube" resulting in the Agent focussing on the blue cube followed by focussing on the red cube.
Results: The Agent learned this task after two training instances.
Learning: During the learning-phase of the experiment, the Agent is rewarded for focussing on the blue cube followed by focussing on the red cube after receiving the text "look blue cube then red cube".
Recall: To test the Agent, the Agent is initialized with its focus on the blue cube and is then presented with the text "look blue cube then red cube" resulting in the Agent focussing on the blue cube followed by focussing on the red cube.
Results: The Agent learned this task after two training instances.
Respond to the text "look blue cube then red cube"
Current Experiments - Understanding Commands
The current experiments are focused on understanding simple human text commands.
Future development and experiments will be focused on improving the Agent's generalization, grammar-understanding and it's ability to proactively discover the knowledge required to fulfil human commands.
Future Experiments - Proactive Discovery
